Abstract
Text-to-3D with diffusion models has achieved remarkable progress in recent years. However, existing methods either rely on score
distillation-based optimization which suffer from slow inference, low diversity and Janus problems, or are feed-forward methods that generate
low quality results due to the scarcity of 3D training data. In this paper, we propose Instant3D, a novel method that
generates high-quality and diverse 3D assets from text prompts in a feed-forward manner.
We adopt a two-stage paradigm, which first generates a sparse set of four structured and consistent views from text in one shot with
a fine-tuned 2D text-to-image diffusion model, and then directly regresses the NeRF from the generated images with a
novel transformer-based sparse-view reconstructor. Through extensive experiments, we demonstrate that our method can generate
high-quality, diverse and Janus-free 3D assets within 20 seconds, which is two order of magnitude faster than previous optimization-based
methods that can take 1 to 10 hours.
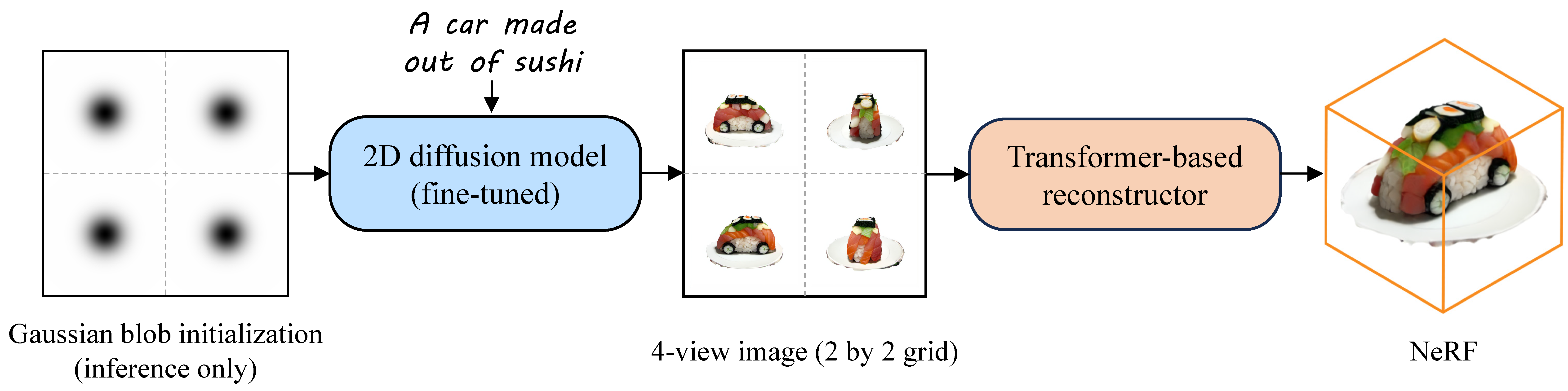
Figure 1. The overall pipeline of Instant3D. We finetune Stable Diffusion with a relatively small amount of 3D data (10K shapes) to generate 2 by 2 grid images, where each quadrant contains a view of the same object at a fixed camera position. A transformer-based reconstructor takes in these 4 view images and outputs a triplane representation of NeRF.